Interpreter Pattern
1. Interpreter 패턴이란
디자인 패턴의 목적 중 하나는 클래스의 재이용성을 높이기 위해서이다. 재이용성이란 한 번 작성한 클래스를 별로 수정하지 않고(가능하면 전혀 수정하지 않고) 몇 번이고 사용할 수 있도록 하는 것이다.
Interpreter 패턴에서는 프로그램이 해결하려는 문제를 간단한 ‘미니 언어’로 표현한다. 구체적인 문제를 미니 언어로 기술된 ‘미니 프로그램’으로 표현한다. 미니 프로그램은 그 자체만으로는 동작하지 않기 때문에 Java 언어로 ‘통역(interpreter)’ 역할을 하는 프로그램을 만들어 둔다. 통역 프로그램은 미니 언어를 해석하고 미니 프로그램을 해석, 실행한다. 이 통역 프로그램을 인터프리터라고도 부른다. 해결해야 할 문제에 변화가 생겼을 때에는 Java 언어로 기술된 프로그램을 수정하는 것이 아니라 미니 프로그램 쪽을 수정해서 대처한다. 이와 같은 패턴을 Interpreter 패턴 이라고 한다.
Java 언어로 프로그래밍을 작성할 경우, 일반적으로 문제에 변화가 생긴 경우, 보통은 Java 언어로 기술된 프로그램을 수정한다. 가능하면 프로그램의 수정은 적게 하고 싶지만, 어쨌든 Java 언어의 프로그램을 수정해야 한다. 그러나 Interpreter 패턴을 사용한 경우에는 Java 언어로 기술된 프로그램은 수정하지 않고, 미니 언어로 기술된 미니 프로그램 쪽을 수정한다.
2. 객체
- Interpreter 패턴의 클래스 다이어그램
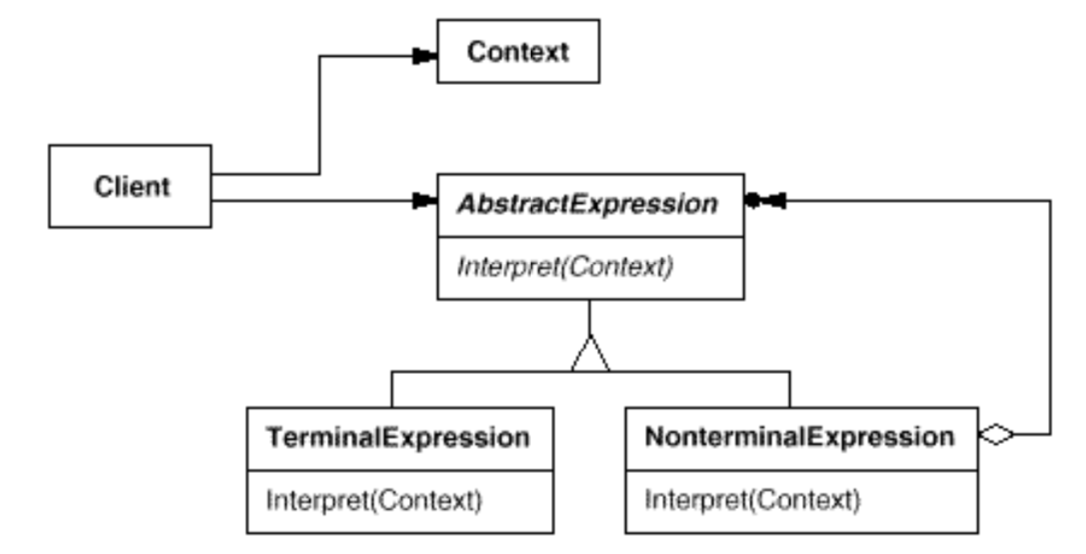
1) AbstractExpression(추상적인 표현)의 역할
구문 트리의 노드에 공통의 인터페이스(API)를 결정하는 역할이다.
2) terminalExpression(종착점 표현)의 역할
BNF의 Terminal Expression에 대응하는 역할이다.
3) NonterminalExpression(비종착점 표현)의 역할
BNF의 Nonterminal Expression에 대응하는 역할이다.
4) Context(문맥, 전후 관계)의 역할
인터피리터가 구문해석을 실행하기 위한 정보를 제공하는 역할이다.
3. 예제
1) Node 클래스
구문 트리의 각 부분(노드)을 구성하는 최상위 클래스이다. Node 클래스에는 추상 메소드 parse만이 선언되어 있다. 이 parse는 ‘구문해석이라는 처리를 실행하기’ 위한 메소드이다. Node 클래스에서는 parse 메소드를 선언만 하고 구체적으로 어떻게 해석할지는 Node 클래스의 하위 클래스 쪽에 위임하고 있다(subclass responsibility).
1
2
3
public abstract class Node {
public abstract void parse(Context context) throws ParseException;
}
2) ProgramNode 클래스
미니 언어의 문법(BNF)에 따라서 클래스 정의를 살펴보면, 먼저 프로그램이라는 program을 나타내는 ProgramNode 클래스이다. 이 클래스에는 Node형의 CommandListNode의 필드가 있다. 이 필드는 자신의 뒤에 이어지는 command list에 대응하는 구조(노드)를 저장하기 위한 것이다.
구문해석을 할 때의 처리단위를 토큰(token)이라고 부른다. 이 미니 언어에서 ‘토큰’은 영어단어와 동의어이지만, 일반적인 프로그래밍 언어에서는 예를 들어 +나 == 등도 토큰이 된다. 좀더 구체적으로 ㅁ라하면 어구해석(lex)은 문자로부터 토큰을 만들고, 구문해석(parse)은 토큰으로부터 구문 트리를 만든다.
이 skipToken 메소드는 program이라는 토큰을 건너뛰고 있다. 그리고 만약 program이라는 토큰이 없으면 ParseException의 예외를 제공한다.
1
2
3
4
5
6
7
8
9
10
11
12
// <program> ::= program <command list>
public class ProgramNode extends Node {
private Node commandListNode;
public void parse(Context context) throws ParseException {
context.skipToken("program");
commandListNode = new CommandListNode();
commandListNode.parse(context);
}
public String toString() {
return "[program " + commandListNode + "]";
}
}
3) CommandListNode 클래스
command가 0번 이상 반복하고 마지막에 end가 온다. 0번 이상 반복하는 command를 저장하기 위해 CommandListNode 클래스는 java.util.ArrayList형의 필드 list를 가지고 있다. 이 필드에 command에 대응하는 CommandNode 클래스의 인스턴스를 저장한다.
여기에서도 또한 BNF에서 기술된 범위 안에서 처리를 실행하고 있는 것을 알 수 있다. 가능한 한 BNF에 충실하게 마치 BNF를 Java로 옮겨놓은 것처럼 프로그래밍하고 있다. 이와 같이 하면 프로그램 오류가 적어진다. 무심코 ‘이렇게 하는 편이 속도를 높일 수 있지 않을까’라는 유혹에 빠져, BNF의 범위를 넘어서는 처리를 하게 되면 생각하지 못한 버그가 발생할 위험성이 있다. Interpreter 패턴은 원래 미니 언어라는 간접적인 처리 방법을 이용하고 있기 때문에, 잔재주로 효율성을 꾀하는 것은 별로 현명한 방법이 아니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import java.util.ArrayList;
// <command list> ::= <command>* end
public class CommandListNode extends Node {
private ArrayList list = new ArrayList();
public void parse(Context context) throws ParseException {
while (true) {
if (context.currentToken() == null) {
throw new ParseException("Missing 'end'");
} else if (context.currentToken().equals("end")) {
context.skipToken("end");
break;
} else {
Node commandNode = new CommandNode();
commandNode.parse(context);
list.add(commandNode);
}
}
}
public String toString() {
return list.toString();
}
}
4) CommandNode 클래스
Node 형의 필드 node는 repeat command에 대응하는 RepeatCommandNode 클래스의 인스턴스, 또는 primitive command에 대응하는 primitiveCommandNode 클래스의 인스턴스를 저장하기 위해 사용된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// <command> ::= <repeat command> | <primitive command>
public class CommandNode extends Node {
private Node node;
public void parse(Context context) throws ParseException {
if (context.currentToken().equals("repeat")) {
node = new RepeatCommandNode();
node.parse(context);
} else {
node = new PrimitiveCommandNode();
node.parse(context);
}
}
public String toString() {
return node.toString();
}
}
5) RepeatCommandNode 클래스
RepeatCommandNode 클래스는 repeat command에 대응하고 있다. number 부분은 int형의 number 필드, command list 부분은 Node 형의 commandListNode 필드에 저장된다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// <repeat command> ::= repeat <number> <command list>
public class RepeatCommandNode extends Node {
private int number;
private Node commandListNode;
public void parse(Context context) throws ParseException {
context.skipToken("repeat");
number = context.currentNumber();
context.nextToken();
commandListNode = new CommandListNode();
commandListNode.parse(context);
}
public String toString() {
return "[repeat " + number + " " + commandListNode + "]";
}
}
6) PrimitiveCommandNode 클래스
이곳의 parse 메소드에서는 다른 parse 메소드를 호출하지 않는다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// <primitive command> ::= go | right | left
public class PrimitiveCommandNode extends Node {
private String name;
public void parse(Context context) throws ParseException {
name = context.currentToken();
context.skipToken(name);
if (!name.equals("go") && !name.equals("right") && !name.equals("left")) {
throw new ParseException(name + " is undefined");
}
}
public String toString() {
return name;
}
}
7) Context 클래스
구문해석을 위해 필요한 메소드를 제공한다.
- Context 클래스가 제공하는 메소드
| 이름 | 해설 |
|---|---|
| nextToken | 다음의 토큰을 얻는다(다음 토큰으로 진행) |
| currentToken | 현재의 토큰을 얻는다(다음 토큰으로는 진행하지 않는다) |
| skipToken | 현재의 토큰을 검사한 후, 다음 토큰을 얻는다(다음 토큰으로 진행) |
| currentNumber | 현재의 토큰을 수치로 얻는다(다음 토큰으로 진행하지 않는다) |
여기에서는 java. util StringTokenizer라는 편리한 클래스를 사용한다. 이 클래스는 주어진 문자열을 토큰으로 분할해준다. 분할할 때의 구분 문자는 공백(‘ ‘), 탭(‘\t’), 줄 바꿈(‘\n’), 캐리지 리턴(‘\r’), 폼 피트(‘\f’)이다.
- Context 클래스를 이용하고 있는 java.util.StringTokenizer의 메소드
| 이름 | 해설 |
|---|---|
| nextToken | 다음 토큰을 얻는다(다음 토큰으로 진행한다) |
| hasMoreTokens | 다음 토큰이 있는지, 없는지를 조사한다 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import java.util.*;
public class Context {
private StringTokenizer tokenizer;
private String currentToken;
public Context(String text) {
tokenizer = new StringTokenizer(text);
nextToken();
}
public String nextToken() {
if (tokenizer.hasMoreTokens()) {
currentToken = tokenizer.nextToken();
} else {
currentToken = null;
}
return currentToken;
}
public String currentToken() {
return currentToken;
}
public void skipToken(String token) throws ParseException {
if (!token.equals(currentToken)) {
throw new ParseException("Warning: " + token + " is expected, but " + currentToken + " is found.");
}
nextToken();
}
public int currentNumber() throws ParseException {
int number = 0;
try {
number = Integer.parseInt(currentToken);
} catch (NumberFormatException e) {
throw new ParseException("Warning: " + e);
}
return number;
}
}
8) ParseException 클래스
구문해석 안의 예외를 위한 클래스이며, 특별한 부분은 없다.
1
2
3
4
5
public class ParseException extends Exception {
public ParseException(String msg) {
super(msg);
}
}
9) Main 클래스
미니 언어의 인터프리터를 작동시키기 위한 클래스이다. Main은 “program.txt”라는 파일을 읽어들여 한 행 한행을 미니 프로그램으로 생각하고 구문해석을 해서 그 결과를 문자열로 표시한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import java.util.*;
import java.io.*;
public class Main {
public static void main(String[] args) {
try {
BufferedReader reader = new BufferedReader(new FileReader("program.txt"));
String text;
while ((text = reader.readLine()) != null) {
System.out.println("text = \"" + text + "\"");
Node node = new ProgramNode();
node.parse(new Context(text));
System.out.println("node = " + node);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
4. 개념 확장
1) 그 외의 미니 언어
① 정규표현
미니 언어의 예로 정규표현(regular expression)이 있다. 여기에는
1
raining & (dogs | cats) *
와 같은 표기를 해석하고 구문 트리를 작성한다. 덧붙여 말하면 위 표현은 raining의 뒤에 dogs 또는 cats가 0번 이상 반복한다는 것을 표현하고 있다.
② 검색용의 표현
단어의 조합을 표현하기 위한 Little Language라는 패턴이 있다. 여기에서는 예를 들어,
1
garlic and not onions
와 같은 표기를 해석해서 구문 트리를 작성하고 있다. 덧붙이면 위 표현은 garlic을 포함하지만 onions는 포함하지 않는 것을 표현하고 있다.
③ 일괄(batch) 처리 언어
기본적인 명령이 몇 가지 준비되어 있고 그것들을 순서대로 실행하거나 반복해서 실행하는 언어(일괄 처리 언어)도 Interpreter 패턴으로 처리할 수 있다.
2) 건너뛸 것인가, 읽을 것인가
인터프리터를 만들고 있을 때 자주 발생하는 것이 토큰을 한 개 많이 읽거나 적게 읽거나 하는 버그이다. 각 nonterminal에 대응하는 메소드를 기술할 때는 항상 ‘이 메소드에 왔을 때 어디까지 토큰을 읽고 있었는지, 이 메소드에서 나갈 때에는 어디까지 토큰을 읽을 것인지’를 염두해 두고 있어야 한다.
[출처 및 참고]
- Java 언어로 배우는 디자인 패턴 입문
- https://itnext.io/easy-patterns-interpreter-58434c94304d