Java Parallel Stream
1. Java의 스트림
Java의 스트림은 데이터 소스를 둘러싼 단순한 래퍼이므로 편리한 방법으로 데이터에 대한 대량 작업을 수행할 수 있다.
데이터를 저장하지 않으며 기본 데이터 소스를 변경하지 않는다. 오히려 데이터 파이프라인에서 기능적 스타일 작업에 대한 지원을 추가한다.
1) 순차 스트림
기본적으로 Java의 모든 스트림 작업은 명시적으로 병렬로 지정되지 않는 한 순차적으로 처리된다.
순차 스트림은 단일 스레드를 사용하여 파이프라인을 처리한다.
1
2
3
4
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
listOfNumbers.stream().forEach(number ->
System.out.println(number + " " + Thread.currentThread().getName())
);
이 순차 스트림의 출력은 예측 가능하다. 목록 요소는 항상 순서대로 인쇄된다.
1
2
3
4
1 main
2 main
3 main
4 main
2) 병렬 스트림
Java의 모든 스트림은 순차에서 병렬로 쉽게 변환될 수 있다.
순차 스트림에 병렬 메서드를 추가하거나 컬렉션의 parallelStream 메서드를 사용하여 스트림을 생성하면 이를 달성할 수 있다.
1
2
3
4
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
listOfNumbers.parallelStream().forEach(number ->
System.out.println(number + " " + Thread.currentThread().getName())
);
병렬 스트림을 사용하면 별도의 코어에서 코드를 병렬로 실행할 수 있다. 최종 결과는 각 개별 결과의 조합이다.
그러나 실행 순서는 통제할 수 없다. 프로그램을 실행할 때마다 변경될 수 있다.
1
2
3
4
4 ForkJoinPool.commonPool-worker-3
2 ForkJoinPool.commonPool-worker-5
1 ForkJoinPool.commonPool-worker-7
3 main
2. Fork-Join Framework
병렬 스트림은 포크 조인 프레임워크와 작업자 스레드의 공통 풀을 사용한다.
여러 스레드 간의 작업 관리를 처리하기 위해 Java 7의 java.util.concurrent에 포크 조인 프레임워크가 추가되었다.
1) 소스 분할
포크 조인 프레임워크는 작업자 스레드 간에 소스 데이터를 분할하고 작업 완료 시 콜백을 처리하는 일을 담당한다.
정수의 합을 병렬로 계산하는 예이니다.
축소 메소드를 사용 하고 0부터 시작하는 대신 시작 합계에 5를 더할 것이다.
1
2
3
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
int sum = listOfNumbers.parallelStream().reduce(5, Integer::sum);
assertThat(sum).isNotEqualTo(15);
순차 스트림에서 이 작업의 결과는 15이다.
그러나 축소 작업은 병렬로 처리되므로 숫자 5는 실제로 모든 작업자 스레드에 합산된다.
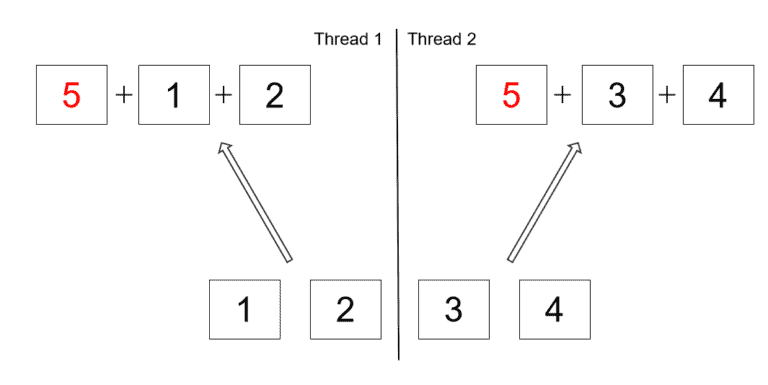
실제 결과는 공통 포크 조인 풀에 사용되는 스레드 수에 따라 다를 수 있다.
이 문제를 해결하려면 병렬 스트림 외부에 숫자 5를 추가해야 한다.
1
2
3
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
int sum = listOfNumbers.parallelStream().reduce(0, Integer::sum) + 5;
assertThat(sum).isEqualTo(15);
따라서 어떤 작업을 병렬로 실행할 수 있는지 주의해야 한다.
2) 공통 스레드 풀
공통 풀의 스레드 수는(프로세서 코어 수 -1)과 같다.
그러나 API를 사용하면 JVM 매개변수를 전달하여 사용할 스레드 수를 지정할 수 있다.
1
-D java.util.concurrent.ForkJoinPool.common.parallelism=4
이는 전역 설정이며 모든 병렬 스트림과 공통 풀을 사용하는 기타 포크 조인 작업에 영향을 미친다. 매우 타당한 이유가 없는 한 이 매개변수를 수정하지 않는 것이 좋다.
3) 사용자 정의 스레드 풀
기본 공통 스레드 풀 외에도 사용자 정의 스레드 풀에서 병렬 스트림을 실행할 수도 있다.
1
2
3
4
5
List<Integer> listOfNumbers = Arrays.asList(1, 2, 3, 4);
ForkJoinPool customThreadPool = new ForkJoinPool(4);
int sum = customThreadPool.submit(() -> listOfNumbers.parallelStream().reduce(0, Integer::sum)).get();
customThreadPool.shutdown();
assertThat(sum).isEqualTo(10);
Oracle에서는 공통 스레드 풀 사용을 권장한다. 사용자 정의 스레드 풀에서 병렬 스트림을 실행하는 데는 매우 타당한 이유가 있어야 한다.
3. 성능에 미치는 영향
다중 코어를 완전히 활용하려면 병렬 처리가 유리할 수 있다. 그러나 다중 스레드 관리, 메모리 지역성, 소스 분할 및 결과 병합에 대한 오버헤드도 고려해야 한다.
1) 오버헤드
정수 스트림의 예이다.
순차 및 병렬 축소 작업에 대한 벤치마크를 실행한다.
1
2
IntStream.rangeClosed(1, 100).reduce(0, Integer::sum);
IntStream.rangeClosed(1, 100).parallel().reduce(0, Integer::sum);
이 간단한 합계 감소에서 순차 스트림을 병렬 스트림으로 변환하면 성능이 저하된다.
1
2
3
Benchmark Mode Cnt Score Error Units
SplittingCosts.sourceSplittingIntStreamParallel avgt 25 35476,283 ± 204,446 ns/op
SplittingCosts.sourceSplittingIntStreamSequential avgt 25 68,274 ± 0,963 ns/op
그 이유는 때때로 스레드, 소스 및 결과를 관리하는 오버헤드가 실제 작업을 수행하는 것보다 더 비싼 작업이기 때문이다.
2) 비용 분할
데이터 소스를 균등하게 분할하는 것은 병렬 실행을 활성화하는데 필요한 비용이지만 일부 데이터 소스는 다른 데이터 소스보다 더 잘 분할된다.
ArrayList와 LinkedList를 사용하여 이를 확인한다.
1
2
3
4
5
6
7
8
9
private static final List<Integer> arrayListOfNumbers = new ArrayList<>();
private static final List<Integer> linkedListOfNumbers = new LinkedList<>();
static {
IntStream.rangeClosed(1, 1_000_000).forEach(i -> {
arrayListOfNumbers.add(i);
linkedListOfNumbers.add(i);
});
}
두 가지 유형의 목록에 대한 순차 및 병렬 축소 작업에 대한 벤치마크를 실행한다.
1
2
3
4
arrayListOfNumbers.stream().reduce(0, Integer::sum)
arrayListOfNumbers.parallelStream().reduce(0, Integer::sum);
linkedListOfNumbers.stream().reduce(0, Integer::sum);
linkedListOfNumbers.parallelStream().reduce(0, Integer::sum);
결과는 순차 스트림을 병렬 스트림으로 변환하면 ArrayList에 대해서만 성능 이점이 있음을 보여준다.
1
2
3
4
5
Benchmark Mode Cnt Score Error Units
DifferentSourceSplitting.differentSourceArrayListParallel avgt 25 2004849,711 ± 5289,437 ns/op
DifferentSourceSplitting.differentSourceArrayListSequential avgt 25 5437923,224 ± 37398,940 ns/op
DifferentSourceSplitting.differentSourceLinkedListParallel avgt 25 13561609,611 ± 275658,633 ns/op
DifferentSourceSplitting.differentSourceLinkedListSequential avgt 25 10664918,132 ± 254251,184 ns/op
그 이유는 배열이 저렴하고 균등하게 분할될 수 있는 반면 LinkedList에는 이러한 속성이 없기 때문이다. TreeMap과 HashSet은 LinkedList 보다 분할이 좋지만 배열만큼 분할되지는 않는다.
3) 비용 병합
병렬 계산을 위해 소스를 분할할 때마다 최종적으로 결과를 결합해야 한다.
다양한 병합 작업으로 합계와 그룹화를 사용하여 순차 및 병렬 스트림에서 벤치마크를 실행한다.
1
2
3
4
arrayListOfNumbers.stream().reduce(0, Integer::sum);
arrayListOfNumbers.stream().parallel().reduce(0, Integer::sum);
arrayListOfNumbers.stream().collect(Collectors.toSet());
arrayListOfNumbers.stream().parallel().collect(Collectors.toSet())
결과는 순차 스트림을 병렬 스트림으로 변환하면 합계 작업에 대해서만 성능 이점이 있음을 보여준다.
1
2
3
4
5
Benchmark Mode Cnt Score Error Units
MergingCosts.mergingCostsGroupingParallel avgt 25 135093312,675 ± 4195024,803 ns/op
MergingCosts.mergingCostsGroupingSequential avgt 25 70631711,489 ± 1517217,320 ns/op
MergingCosts.mergingCostsSumParallel avgt 25 2074483,821 ± 7520,402 ns/op
MergingCosts.mergingCostsSumSequential avgt 25 5509573,621 ± 60249,942 ns/op
축소 및 추가와 같은 일부 작업의 경우 병합 작업은 정말 저렴하지만 sets나 maps으로 그룹화하는 것과 같은 병합 작업은 상당히 비쌀 수 있다.
4) 메모리 지역성
최신 컴퓨터는 정교한 다단계 캐시를 사용하여 자주 사용되는 데이터를 프로세서 가까이에 보관한다. 선형 메모리 액세스 패턴이 감지되면 하드웨어는 곧 필요할 것이라는 가정하에 다음 데이터 라인을 프리페치한다.
병렬화는 프로세서 코어가 유용한 작업을 수행하도록 유지할 수 있을 때 성능상의 이점을 제공한다. 캐시 누락을 기다리는 것은 유용한 작업이 아니므로 메모리 대역폭을 제한 요소로 고려해야 한다.
두 개의 배열을 사용하여 이를 확인한다. 하나는 기본 유형을 사용하고 다른 하나는 객체 데이터 유형을 사용한다.
1
2
3
4
5
6
7
8
9
private static final int[] intArray = new int[1_000_000];
private static final Integer[] integerArray = new Integer[1_000_000];
static {
IntStream.rangeClosed(1, 1_000_000).forEach(i -> {
intArray[i-1] = i;
integerArray[i-1] = i;
});
}
두 어레이의 순차 및 병렬 축소 작업에 대한 벤치마크를 실행한다.
1
2
3
4
Arrays.stream(intArray).reduce(0, Integer::sum);
Arrays.stream(intArray).parallel().reduce(0, Integer::sum);
Arrays.stream(integerArray).reduce(0, Integer::sum);
Arrays.stream(integerArray).parallel().reduce(0, Integer::sum);
결과는 순차 스트림을 병렬 스트림으로 변환하면 기본 요소 배열을 사용할 때 약간 더 많은 성능 이점을 제공한다.
1
2
3
4
5
Benchmark Mode Cnt Score Error Units
MemoryLocalityCosts.localityIntArrayParallel sequential stream avgt 25 116247,787 ± 283,150 ns/op
MemoryLocalityCosts.localityIntArraySequential avgt 25 293142,385 ± 2526,892 ns/op
MemoryLocalityCosts.localityIntegerArrayParallel avgt 25 2153732,607 ± 16956,463 ns/op
MemoryLocalityCosts.localityIntegerArraySequential avgt 25 5134866,640 ± 148283,942 ns/op
프리미티브 배열은 Java에서 가능한 최상의 지역성을 제공한다. 일반적으로 데이터 구조에 포인터가 많을수록 참조 개체를 가져오기 위해 메모리에 더 많은 압력을 가하게 된다. 여러 코어가 동시에 메모리에서 데이터를 가져오므로 이는 병렬화에 부정적인 영향을 미칠 수 있다.
5) NQ 모델
Oracle은 병렬화가 성능 향상을 제공할 수 있는지 여부를 판단하는데 도움이 되는 간단한 모델을 제시했다. NQ 모델에서 N은 소스 데이터 요소의 수를 나타내고, Q는 데이터 요소당 수행된 계산량을 나타낸다.
N*Q 곱이 클수록 병렬화로 인해 성능이 향상될 가능성이 높다. 숫자 합산과 같이 사소하게 작은 Q 문제의 경우 경험 법칙에 따르면 N은 10,000보다 커야 한다. 계산 횟수가 증가하면 병렬 처리를 통해 성능을 향상하는데 필요한 데이터 크기가 줄어든다.
6) 파일 검색 비용
병렬 스트림을 사용한 파일 검색은 순차 스트림에 비해 성능이 더 좋다. 1500개 이상의 텍스트 파일을 검색하기 위해 순차 및 병렬 스트림에서 벤치마크를 실행한다.
1
2
3
4
5
Files.walk(Paths.get("src/main/resources/")).map(Path::normalize).filter(Files::isRegularFile)
.filter(path -> path.getFileName().toString().endsWith(".txt")).collect(Collectors.toList());
Files.walk(Paths.get("src/main/resources/")).parallel().map(Path::normalize).filter(Files::
isRegularFile).filter(path -> path.getFileName().toString().endsWith(".txt")).
collect(Collectors.toList());
결과는 순차 스트림을 병렬 스트림으로 변환하면 더 많은 수의 파일을 검색할 때 약간 더 많은 성능 이점을 제공한다.
1
2
3
Benchmark Mode Cnt Score Error Units
FileSearchCost.textFileSearchParallel avgt 25 10808832.831 ± 446934.773 ns/op
FileSearchCost.textFileSearchSequential avgt 25 13271799.599 ± 245112.749 ns/op
4. 병렬 스트림을 사용해야 하는 경우
병렬 스트림을 사용할 때는 매우 신중해야 한다.
병렬화는 특정 사용 사례에서 성능상의 이점을 가져올 수 있다. 그러나 병렬 스트림은 마법 같은 성능 향상 도구로 간주될 수 없다. 따라서 개발 중에도 순차 스트림을 기본값으로 사용해야 한다.
실제 성능 요구 사항이 있는 경우 순차 스트림을 병렬 스트림으로 변환할 수 있다. 이러한 요구 사항을 고려할 때 먼저 성능 측정을 실행하고 가능한 최적화 전략으로 병렬성을 고려해야 한다.
요소당 수행되는 많은 양의 데이터와 많은 계산은 병렬 처리가 좋은 옵션이 될 수 있음을 나타낸다.
반면에, 적은 양의 데이터, 고르지 않게 분할된 소스, 비용이 많이 드는 병합 작업 및 열악한 메모리 지역성은 병렬 실행에 잠재적인 문제를 나타낸다.