Redis란
1. Redis란
레디스(Redis)는 Remote Dictionary Server의 약자로서, “키-값” 구조의 비정형 데이터를 저장하고 관리하기 위한 오픈 소스 기반의 비관계형 데이터베이스 관리 시스템(DBMS)이다.

2009년 살바토르 산필리포(Salvatore Sanfilippo)가 처음 개발했다. 2015년부터 Redis Labs가 지원하고 있다. 모든 데이터를 메모리로 불러와서 처리하는 메모리 기반 DBMS이다. BSD 라이선스를 따른다.
DB-Engines.com의 월간 랭킹에 따르면, 레디스는 가장 인기 있는 키-값 저장소이다.
2. 데이터 구조
개발자를 염두에 두고 설계된 단순한 키-값 데이터 저장소와 달리 Redis 데이터 구조는 최신 애플리케이션의 다양한 사용 사례에 대해 데이터를 모델링하는 유연한 방법을 제공한다. 이러한 정교한 데이터 구조를 통해 데이터를 저장, 액세스 및 사용할 수 있는 고급 코드 라인이 적은 애플리케이션을 개발하고 강력하고 빠른 메모리 내 처리가 가능하다.
이러한 데이터 구조는 모든 데이터베이스 작업에 대해 응용 프로그램 개체를 데이터베이스 엔터티로 변환하는 것과 관련된 오버헤드를 방지한다.
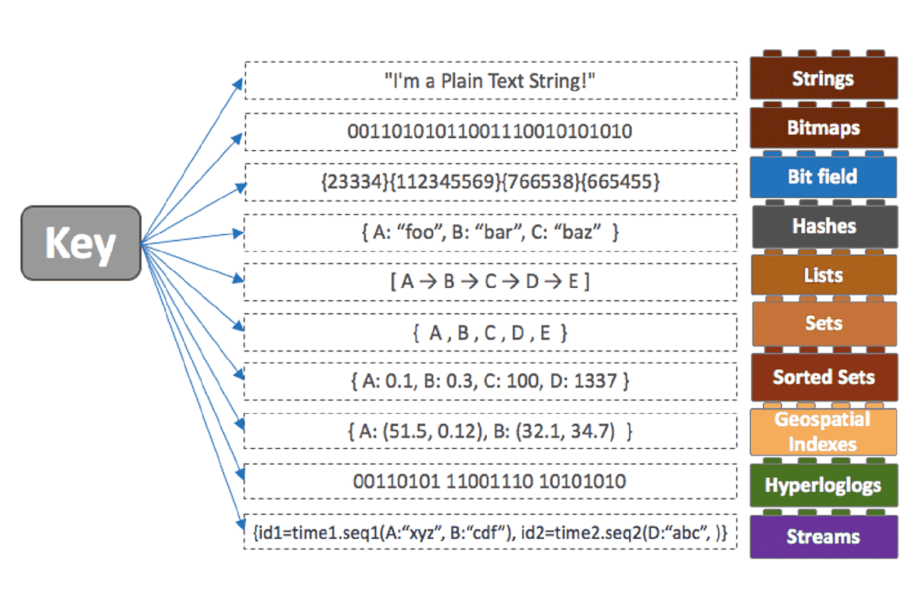
Redis는 Strings, Hashes, Lists, Sets, Sorted Sets, Bitmaps, Bitfields, HyperLogLog, Geospatial indexes, Streams를 기본 데이터 구조로 제공한다. 모든 데이터 구조에 대해 Redis는 다중 유형 작업을 효과적인 방식으로 실행할 수 있도록 전용 명령을 유지 관리한다.
1) Strings
Redis의 가장 다양한 빌딩 블록 중 하나인 Redis Strings는 바이너리 안전 데이터 구조이다. 문자열, 정수, 부동 소수점 값, JPEG 이미지, 직렬화된 Ruby 객체 또는 기타 원하는 모든 종류의 데이터를 저장할 수 있다. 전체 문자열 또는 부분에 대해 연산하고 정수 및 부동 소수점을 증가 또는 감소시킨다.
2) Sets
Redis Sets 데이터 구조는 고유한 구성원 집합을 저장한다. 세트를 사용하여 구성원을 추가, 가져오기 또는 제거하고 구성원 자격을 확인하거나 임의의 구성원을 검색할 수 있다. 또한 교집합, 합집합 및 차집합과 같은 집합 연산을 수행하고 집합 카디널리티를 계산할 수 있다.

3) Sorted Sets
Redis 정렬 집합에는 부동 소수점 점수로 정렬된 고유한 구성원 집합이 포함되어 있다. 집합과 마찬가지로 개별 구성원을 추가, 가져오기 또는 제거하고 합집합, 교집합, 차이 집합 및 카디널리티 계산과 같은 집합 작업을 수행할 수 있다. 또한 점수 또는 구성원 값, 집계, 필터 및 주문 결과를 기반으로 집합을 쿼리할 수도 있다.

4) Lists
Redis 목록은 삽입 순서에 따라 정렬된 문자열 요소 컬렉션을 보유한다. 양쪽 끝에서 항목을 밀거나 팝하고, 오프셋을 기준으로 자르고, 개별 또는 여러 항목을 읽거나, 값 및 위치별로 항목을 찾거나 제거한다. 또한 비동기 메시지 전송에 대한 차단 호출을 만들 수도 있다.

5) Hashes
문서 저장소의 문서나 관계형 데이터베이스의 행과 유사하게 Redis 해시 구조는 필드-값 쌍 세트를 저장한다. 개별 항목을 추가, 가져오기 또는 제거하고 전체 해시를 가져오거나 해시에서 하나 이상의 필드를 카운터로 사용하는 기능을 제공한다.

6) Bitmaps
Redis Bitmaps은 이진 논리 및 상태를 저장하는 컴팩트한 데이터 구조이다. 주어진 위치에서 비트 값을 가져오고 설정하며 여러 비트맵 키 사이에서 AND, OR, XOR 및 NOT 연산을 수행하는 명령을 제공한다.

7) Bitfields
Bitfields는 단일 어레이에서 여러 카운터를 구현하는 효율적이고 간결한 방법을 제공한다. 주어진 위치에서 카운터를 증가 및 감소시킬 수 있으며 카운터가 상한에 도달하면 플래그가 오버플로된다.

8) HyperLogLog
Redis HyperLogLog는 일정한 메모리 크기에서 고유한 값(카디널리티 설정)을 계산하는 데 사용되는 확률적 데이터 구조이다. 메모리 효율성으로 많은 고유 항목을 추가 및 계산하고 둘 이상의 HyperLogLog 데이터 구조를 하나로 병합할 수 있다.

9) Geospatial indexes
지리 공간 인덱스는 Redis에서 지리 공간 데이터를 관리하고 사용하는 매우 효율적이고 간단한 방법을 제공한다. 위도와 경도가 있는 고유한 항목을 추가하고, 개체 간의 거리를 계산하고, 위치에서 주어진 반경 범위 내의 구성원을 찾을 수 있다.
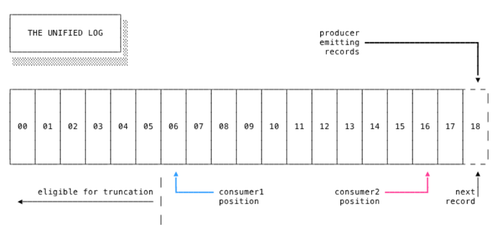
10) Streams
Redis Streams는 메시지 대기열과 같은 고속 데이터 스트림을 관리하기 위한 매우 강력한 데이터 구조이다. 즉시 사용 가능한 파티셔닝, 복제 및 지속성을 통해 밀리초 미만의 대기 시간으로 초당 수백만 개의 데이터 포인트를 캡처하고 처리할 수 있다.
Redis Streams는 범위 및 조회 쿼리를 매우 빠르게 만드는 효율적인 기수 트리 구현을 기반으로 한다. 생산자와 소비자를 비동기 호출로 연결하고 소비자 그룹을 지원한다.