Oracle 중복 데이터 하나만 남기고 제거
Oracle 중복 데이터 하나만 남기고 제거
1. 중복 데이터 제거
오라클에서 조회된 데이터에서 특정 컬럼을 기준으로 하나의 행만 조회해야 하는 경우가 있다.
중복된 컬럼의 데이터에서 그룹별로 최신의 행 하나만 가져오거나, 특정 컬럼으로 정렬하여 최상위 하나의 행만 조회할 때 아래 방법을 사용할 수 있다.
아래의 방법은 행 전체를 중복 체크를 하여 제거하는 방법(DISTINCT)이 아니고 특정 컬럼을 기준으로 중복을 제거하는 방법이다.
2. 그룹별로 순번을 지정하여 하나의 행만 추출
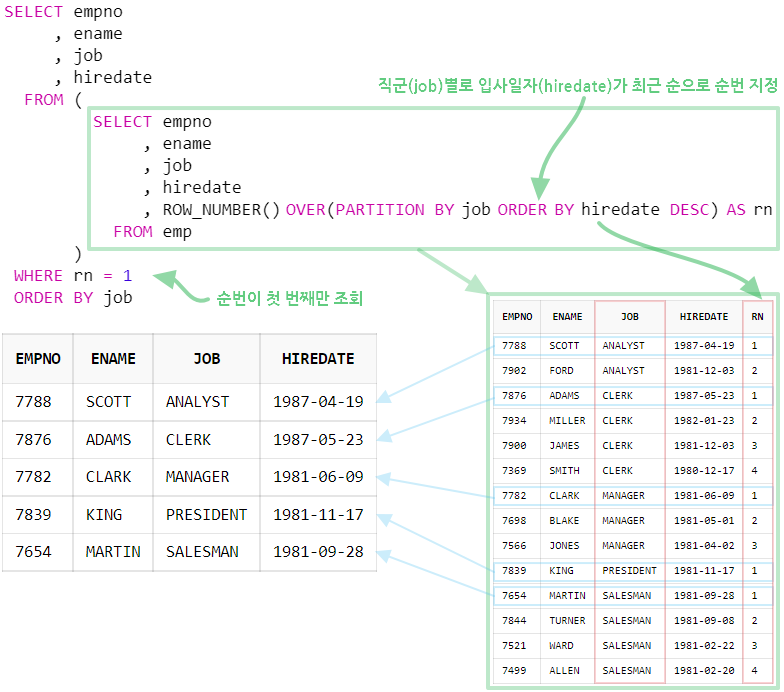
첫 번째 방법은 ROW_NUMBER 함수를 사용하여 직군(job)별 최근 입사 일자(hiredate) 순으로 순번을 부여한 후, 해당 데이터를 인라인 뷰로 사용하여 직군별 첫 번째 순번(rn=1)만 조회하는 방법이다.
위의 방법을 사용하면 GROUP BY 절이나 DISTINCT 키워드를 사용하지 않고도 특정 컬럼을 그룹으로 하나의 데이터만 조회를 할 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
SELECT empno
, ename
, job
, hiredate
FROM (
SELECT empno
, ename
, job
, hiredate
, ROW_NUMBER() OVER (PARTITION BY job ORDER BY hiredate DESC) AS rn
FROM emp
)
WHERE rn = 1
ORDER BY job
3. 그룹별로 MAX에 해당하는 행만 추출
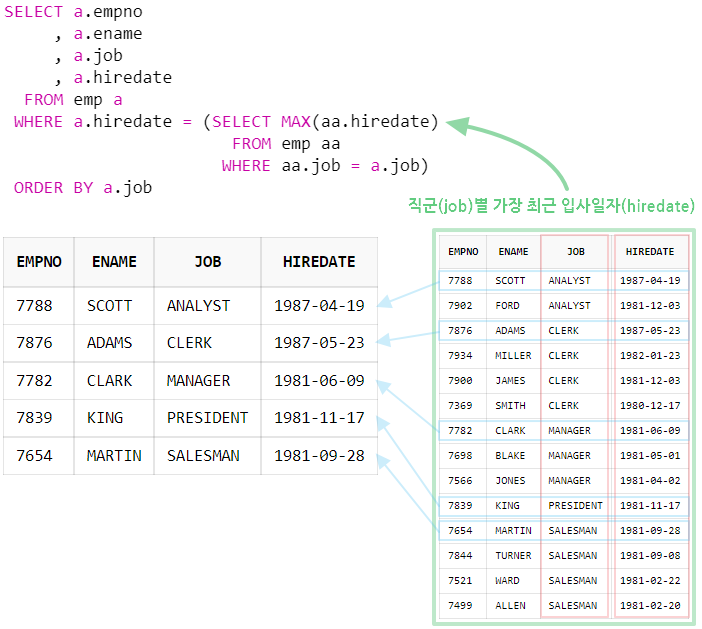
두 번째 방법이다. 아래 예제는 직군(job)별로 최근 입사 일자(hiredate)를 조회하여 해당 직군의 가장 최근 입사 일자에 해당하는 사원만 조회하는 방법이다. 직군별로 최근 입사 일자가 동일한 사원이 존재한다면 2명 이상이 조회될 수 있다.
그룹별로 MAX 값을 가져올 때 조인 컬럼(aa.job)에 인덱스가 존재하지 않는다면 속도가 느려질 수 있으니, 데이터가 많은 테이블인 경우 해당 컬럼에 인덱스가 존재하는지 확인한다.
1
2
3
4
5
6
7
8
9
SELECT a.empno
, a.ename
, a.job
, a.hiredate
FROM emp a
WHERE a.hiredate = (SELECT MAX(aa.hiredate)
FROM emp aa
WHERE aa.job = a.job)
ORDER BY a.job
[출처 및 참고]
This post is licensed under CC BY 4.0 by the author.