Spring Batch란
1. Spring Batch란
Spring Batch는 일괄 처리를 위한 오픈 소스 프레임워크이다. 최신 엔터프라이즈 시스템에서 흔히 볼 수 있는 강력한 배치 애플리케이션을 개발할 수 있도록 설계된 가볍고 포괄적인 솔루션이다.
Spring Batch는 Spring Framework의 POJO 기반 개발 접근 방식을 기반으로 한다.
Spring Batch는 로깅/추적, 트랜잭션 관리, 작업 처리 통계, 작업 재시작, 건너뛰기, 리소스 관리 등 대용량 레코드 처리에 필수적인 재사용 가능한 기능을 제공한다.
또한 최적화 및 파티셔닝 기술을 통해 대용량 및 고성능 배치 작업을 가능하게 하는 고급 기술 서비스 및 기능을 제공한다.
단순하고 복잡한 대용량 배치 작업은 프레임워크를 확장성이 뛰어난 방식으로 활용하여 상당한 양의 정보를 처리할 수 있다.
Spring Batch는 Spring 포트폴리오의 일부이다.
2. 스프링 배치 아키텍처와 구성요소
1) 스프링 배치 구조

- Run Tier
- Application의 scheduling, 실행을 담당.
- 스프링배치는 따로 Scheduling의 기능은 제공하지 않음
- Quartz나 Cron을 이용하도록 권고
- Job Tier
- 전체적인 Job의 수행을 책임진다
- Job 내의 각 Step을 정책에 따라 순차적으로 수행
- Application tier
- Job을 수행하는데 필요한 component
- Data tier
- Database, File 등 물리적 데이터소스
2) 스프링 배치 구성요소
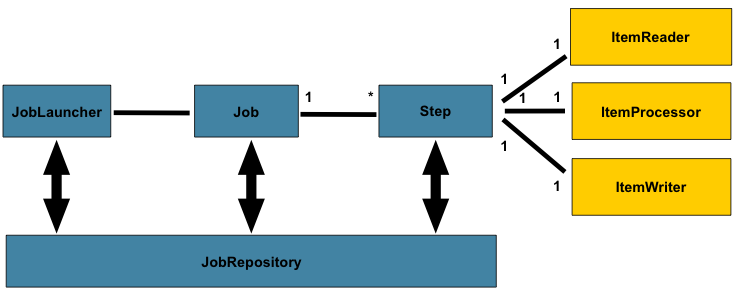
- JobLauncher
- JobLauncher는 배치 Job을 실행시키는 역할
- Job과 Parameter를 받아서 실행하고 JobExecution를 반환
- JobLauncher.java
1
2
3
public interface JobLauncher {
public JobExecution run(Job job, JobParameters jobParameters) throws JobExecutionAlreadyRunningException, JobRestartException, JobInstanceAlreadyCompleteException;
}
- Job
- 실행시킬 작업을 의미
- 논리적인 Job 실행의 개념
- Job configuration과 대응되는 단위
- Job.java
1
2
3
4
5
public interface Job {
String getName(); // 작업의 이름
boolean isRestartable(); // 재시작 가능여부
void execute(JobExecution execution); // 작업을 실행
}
- JobParameter
- Batch Job을 시작하는데 사용하는 파라미터의 집합으로 Job이 실행되는 동안에 Job을 식별하거나 Job에서 참조하는 데이터로 사용
- JobInstance
- 논리적인 Job 실행
- JobInstance = Job + JobParameter
- JobExecution
- 단 한 번 시도되는 Job 실행을 의미하는 기술적인 개념
- 시작 시간, 종료 시간, 상태(시작됨, 완료, 실패), 종료 상태의 속성을 가짐
- JobRepository
- 수행되는 Job에 대한 정보를 담고 있는 저장소
- 어떠한 Job이 언제 수행되었고, 언제 끝났으며, 몇 번이 실행되었고 실행에 대한 결과가 어떤지 등의 Batch 수행과 관련된 모든 meta data가 저장되어 있음
- Step
- Batch Job을 구성하는 독립적인 하나의 단계
- Job은 하나 이상의 step으로 구성
- 실제 배치 처리 과정을 정의하고, 제어하는데 필요한 모든 정보를 포함
- Step의 내용은 전적으로 개발자의 선택에 따라 구성됨
- Step Execution
- 하나의 Step을 실행하는 한 번의 시도
- 시작 시간, 종료 시간, 상태, 종료 상태, commitCount, itemCount의 속성을 가짐
- Item
- 처리할 데이터의 가장 작은 구성 요소
- 예) 파일의 한 줄, DB의 한 Row, XML의 특정 element
- ItemReader
- Step안에서 File 또는 DB등에서 Item을 읽어 들임
- 더 읽어올 Item이 없을 때는 read() 메소드에서 null 값을 반환하며 그 전까지는 순차적인 값을 리턴
- ItemWriter
- Step 안에서 File 또는 DB 등으로 Item을 저장
- Item Processor
- ItemReader에서 읽어 들인 Item에 대하여 필요한 로직처리 작업을 수행
- Chunk
- 하나의 Transaction 안에서 처리할 Item의 덩어리
- chunk size가 10이라면 하나의 transaction 안에서 10개의 item에 대해 처리를 하고 commit을 하게 됨
3. 런타임 메타데이터 모델
스프링 배치는 배치 실행에 관련한 모든 정보를 DB에 저장하고, 참조하며 순차적으로 실행한다. 이러한 형태를 런타임 메타데이터 모델이라 한다.
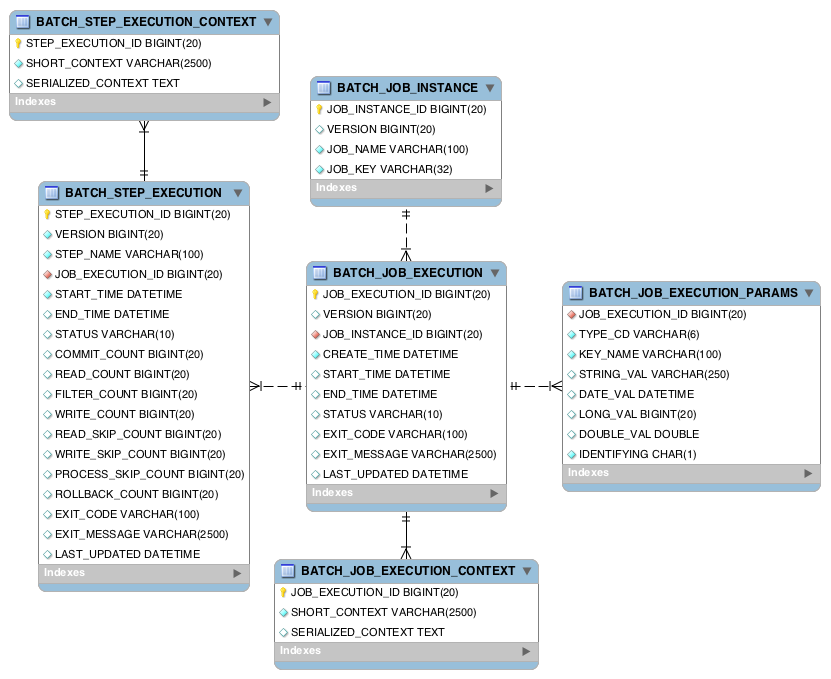
4. STEP을 구성하는 Tasklet과 Chunk 지향 처리
1) Tasklet
Tasklet은 하나의 메서드로 구성 되어있는 간단한 인터페이스이다. 이 메서드 는 실패를 알리기 위해 예외를 반환 하거나 throw할 때까지 execute를 반복적으로 호출하게 된다.

- Job Class 안에 Tasklet 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.batch.core.Job;
import org.springframework.batch.core.Step;
import org.springframework.batch.core.configuration.annotation.JobBuilderFactory;
import org.springframework.batch.core.configuration.annotation.JobScope;
import org.springframework.batch.core.configuration.annotation.StepBuilderFactory;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Slf4j
@RequiredArgsConstructor
@Configuration
public class DemoJobConfig {
@Autowired
private JobBuilderFactory jobBuilderFactory;
@Autowired
private StepBuilderFactory stepBuilderFactory;
@Bean
public Job demoJob() {
return jobBuilderFactory.get("demoJob")
.start(demoStep1())
.next(demoStep2())
.next(demoStep3())
.build();
}
@Bean
@JobScope
public Step demoStep1() {
return stepBuilderFactory.get("demoStep1")
.tasklet((contribution, chunkContext) -> {
log.info("### This is Step1");
return RepeatStatus.FINISHED;
})
.build();
}
}
2) Chunk
Spring Batch에서의 Chunk란 처리 되는 커밋 row 수를 의미한다. Batch 처리에서 커밋 되는 row 수라는건 chunk 단위로 Transaction을 수행하기 때문에 실패시 Chunk 단위 만큼 rollback이 되게 된다.
Chunk 지향 처리에서는 다음과 같은 3가지 시나리오로 실행 된다.
- 읽기(Read)
- Database에서 배치처리를 할 Data를 읽어온다.
- 처리(Processing)
- 읽어온 Data를 가공,처리를 한다. (필수사항 아님)
- 쓰기(Write)
- 가공, 처리한 데이터를 Database에 저장한다.

Chunk 지향 처리에서 배치가 수행되는 시퀸스 다이어그램 이다.

- 처리
1
2
3
4
5
6
7
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
Object item = itemReader.read()
Object processedItem = itemProcessor.process(item);
items.add(processedItem);
}
itemWriter.write(items);
[출처 및 참고]
- https://en.wikipedia.org/wiki/Spring_Batch
- https://wiki.gurubee.net/pages/viewpage.action?pageId=4949437
- https://docs.spring.io/spring-batch/docs/current/reference/html/
- https://khj93.tistory.com/entry/Spring-Batch%EB%9E%80-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B3%A0-%EC%82%AC%EC%9A%A9%ED%95%98%EA%B8%B0
- https://docs.spring.io/spring-batch/docs/3.0.x/reference/html/metaDataSchema.html