XML 파싱시 text 처리
XML 파싱시 text 처리
1. 파싱 XML
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
<response>
<header>
<resultCode>00</resultCode>
<resultMsg>NORMAL SERVICE.</resultMsg>
</header>
<body>
<items>
<item>
<stationName>소사본동</stationName>
<addr>경기 부천시 경인옛로 73소사어울마당 소향관</addr>
<year>1986</year>
<oper>한국환경공단 수도권지역본부</oper>
<vrml></vrml>
<mangName>도시대기</mangName>
<item>SO2, CO, O3, NO2, PM10, PM2.5</item>
<dmX>37.480033</dmX>
<dmY>126.799906</dmY>
</item>
<item>
<stationName>내동</stationName>
<addr>경기 부천시 삼작로 109신흥동주민센터 앞 도로변</addr>
<year>1986</year>
<oper>경기도보건환경연구원</oper>
<vrml></vrml>
<mangName>도시대기</mangName>
<item>SO2, CO, O3, NO2, PM10, PM2.5</item>
<dmX>37.5203</dmX>
<dmY>126.7737</dmY>
</item>
</items>
<numOfRows>10</numOfRows>
<pageNo>1</pageNo>
<totalCount>5</totalCount>
</body>
</response>
2. 문제 및 원인
XML 파싱시 노드 사이의 공백을 텍스트 노드로 인식하여 #text 노드가 생성 된다.
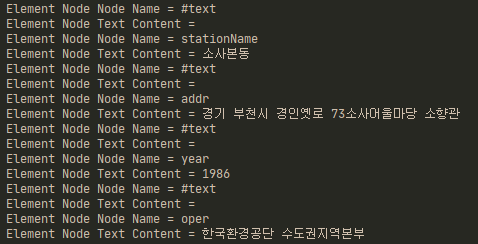
3. 해결
Node Type인 ELEMENT_NODE와 TEXT_NODE를 비교하여 처리한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.InputSource;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathExpression;
import javax.xml.xpath.XPathFactory;
import java.io.IOException;
import java.io.StringReader;
import java.net.URLEncoder;
import java.util.logging.Logger;
public class Parsing {
private static void xmlParsing(String resultXml) {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
factory.setNamespaceAware(true);
DocumentBuilder builder;
Document doc = null;
try {
InputSource is = new InputSource(new StringReader(resultXml));
builder = factory.newDocumentBuilder();
doc = builder.parse(is);
XPathFactory xpathFactory = XPathFactory.newInstance();
XPath xpath = xpathFactory.newXPath();
XPathExpression expr = xpath.compile("//items/item");
NodeList nodeList = (NodeList) expr.evaluate(doc, XPathConstants.NODESET);
int nodeListLength = nodeList.getLength();
for (int i = 0; i < nodeListLength; i++) {
NodeList child = nodeList.item(i).getChildNodes();
int childLength = child.getLength();
for (int j = 0; j < childLength; j++) {
Node node = child.item(j);
if (node.getNodeType() == Node.ELEMENT_NODE) {
System.out.println("Element Node Node Name = " + node.getNodeName());
System.out.println("Element Node Text Content = " + node.getTextContent());
}
if (node.getNodeType() == Node.TEXT_NODE) {
System.out.println("Text Node Node Name = " + node.getNodeName());
System.out.println("Text Node Text Content = " + node.getTextContent());
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
4. 결과
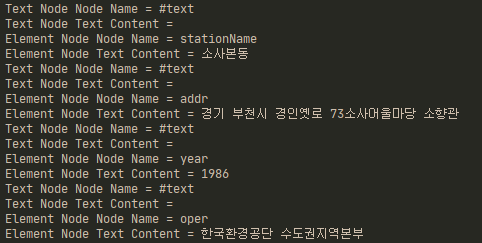
[출처 및 참고]
This post is licensed under CC BY 4.0 by the author.